👣 개요
웹 스크래핑은 웹 사이트의 HTML 파일에서 원하는 정보를 추출하는 작업을 일컫는다.
예를 들어, 네이버 뉴스 페이지에서 각 기사의 제목, 내용, 댓글 등등을 가져오는 작업을
웹 스크래핑이라고 부를 수 있다.
웹 크롤링은 웹 사이트 소유자가 허용하지 않으면 법적으로 문제가 생길 수도 있으니 주의해야 한다.
뿐만 아니라 웹 크롤링을 하기 위해 서버에 허용 횟수 이상의 Request를 보낼 수도 있는데
이는 DDos 공격으로 간주될 수도 있으니 주의해야 한다.
👣 robots.txt
User-agent: *
Disallow: /private/
Disallow: /admin/
Allow: /public/Robot.txt는 웹 사이트 사용자가 어떤 페이지를 크롤링해도 되는지를 명시해놓은 웹페이지다.
해당 페이지는 단순히 알고 싶은 웹 페이지의 Root 주소에 /robots.txt를 붙이면 된다.
https://www.google.com/robots.txt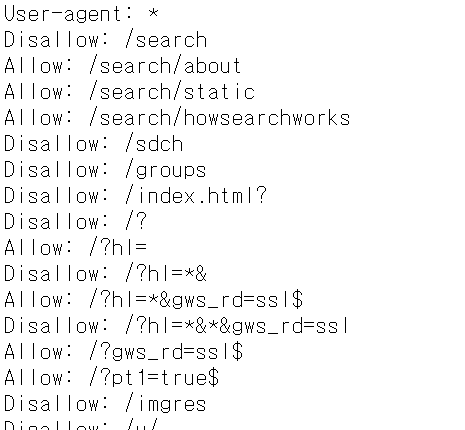
👣 Python Code - 정적 크롤링
1. 관련 라이브러리 설치
pip install requests bs42. 웹 사이트에 Html 파일 요청 보내기.
import requests
req = requests.get('https://www.google.com/')
html = req.text
''' 출력 내용.
<html dir="ltr" lang="ko" class="focus-outline-visible" lazy-loaded="true"><head>
<meta charset="utf-8">
<title>새 탭</title>
<style>
...
</style>
<script type="module" src="./lazy_load.js"></script></body></html>
'''3. 해당 Html 내용을 쉽게 추출하는 도구인 beautifulsoup를 사용함.
from bs4 import BeautifulSoup
# BeautifulSoup 인스턴스 생성.
soup = BeautifulSoup(html, 'html.parser')
# 원하는 DOM 요소를 추출.
main_div = soup.select_one("#mainContent")
👣 BeautifulSoup 문법
태그명으로 찾기 - find(), find_all()
# 매칭되는 첫 요소만 가져오기.
result = soup.find('tag_name')
# or
# 매칭되는 모든 요소 가져오기.
results = soup.find_all('tag_name')CSS 선택자로 찾기 - select(), select_one()
# CSS 선택자 조건에 부합하는 요소 모두를 가져옴.
results = soup.select('#id')
# or
# CSS 선택자 조건에 부합하는 요소 중 첫 번째 요소만 가져옴.
result = soup.select_one('.class')기존에 찾은 요소의 관계를 이용해서 찾기 - find_parent(), findChildren(), find_next_sibling()
# 요소를 찾고 element에 담아내기.
element = soup.select_one('#id')
# 부모 요소 찾기.
parent_element = element.find_parent()
# 자식 요소 찾기.
children_element = element.findChildren()
# 동일 수준의 요소 중 기준 요소 다음에 존재하는 요소 찾기.
sibling_element = element.find_next_sibling()DOM 요소 객체의 속성
# 예시
# <some_tag id="something" attr=value> content </some_tag>
# 요소를 찾고 element에 담아내기.
element = soup.select_one('#something')
# 태그명 출력.
tag_name = element.name
print("태그명:", tag_name) # some_tag
# 요소 내용 출력
text_content = element.text
print("텍스트 내용:", text_content) # content
# 특정 속성 조회.
attribute = element.get('attr')
print("속성 값:", attribute) # value'항해 99' 카테고리의 다른 글
| OG 메타 태그 (0) | 2023.08.06 |
|---|---|
| Pymongo 사용법 (0) | 2023.08.06 |
| Jinja2 템플릿 엔진 (0) | 2023.08.05 |
| Flask 맛보기 (0) | 2023.08.05 |
| mongo Atlas (0) | 2023.08.04 |