
👣 개요
해당 챕터는 JPA의 사용이유, 개선 포인트에 집중하는 부분이다.
👣 기존 문제점 - JDBC 만을 사용할 때의 문제점

JDBC는 Application과 DB 사이를 연결하는 추상화 인터페이스로서
DB 제조업체는 JDBC에서 명시한 API를 기준으로 자바와 연결하는 드라이버를 제작하고
Application 제작자 또한 JDBC에서 명시된 API를 기준으로 DB를 사용한다.
간단한 JDBC를 이용한 DB 통신 방법은 다음과 같다.
GitHub - iksadNorth/Lab_JDBC
Contribute to iksadNorth/Lab_JDBC development by creating an account on GitHub.
github.com
간단하게 코드만 보여준다면 다음과 같이 메서드가 SQL에 종속적인 모습을 볼 수 있다.

만약 위와 같이 만들어 놓고 그대로 놔둘꺼라면 상관없겠지만
만약 새로운 기능을 추가하거나 수정해야 한다면,
위 코드는 단순히 SQL 쿼리문만 고치고 끝날 일이 아닐 것이다.
새로운 SQL에 대한 RowMapper를 작성하고 새로운 ? 위치에 맞게 Parameter를 추가해야 한다.
이는 Human Error를 빈번하게 발생시키고 유지보수 비용을 크게 늘린다.
위 Git Repo에서는 재연하지 못했지만 만약 Member 엔티티에 연관된 객체인 Team을 추가한다고 생각해보자.
객체 지향적인 Java에서는 단순히 클래스에 Team 타입의 필드를 추가하면 된다지만,
SQL에서는 Team을 로드하고 싶다면 Join을 사용해서 같이 가져와줘야 한다.
이것은 추가적인 쿼리 작성을 요구하고 위에서 언급한 유지보수 비용을 늘린다.
결론적으론 다음과 같은 문제가 JDBC에서 보인다.
- SQL에 극도로 의존적이다.
- 엔티티를 DB에서 불러온다해도 연관된 객체를 가져온 것인지 인지하기 어렵다.
- 진정한 의미의 계층 분할이 어렵다.
- Service 계층와 DAO 계층 사이의 의존성[연관 객체 때문에] - 생산성이 낮고 유지보수 비용이 크다.
👣 JPA 탄생 이유
JPA는 객체를 DB에 저장하고 관리할 때,
직접 SQL을 작성하는 것이 아니라 JPA의 API를 이용할 수 있게 도와준다.
즉, SQL을 작성하지 않고도 Java 코드만으로 DB를 관리하는 기술이다.
👣 패러다임 불일치
Java는 객체 지향적 프로그램이고 SQL는 그렇지 못하다.
때문에 서로의 언어에서 가능한 것이 상대편의 언어에서는 사용할 수 없는 일들이 많다.
다음은 그 패러다임 불일치의 예시들이다.
1. 상속
OOP는 상속 기능을 가지고 있지만 SQL은 그렇지 못하다.
그나마 SQL은 슈퍼타입 서브 타입 관계를 사용하면 유사하게 설계할 수 있다.


제아무리 유사하게 설계한다하더라도 실제로 사용할 때는
OOP에서의 Album 객체를 저장하기 위해
SQL에서는 ITEM, ALBUM라는 2개의 테이블에 저장해야 구현가능하다.
2. 연관 관계
OOP에서는 하나의 객체의 필드에 또다른 객체를 보관할 수 있다.
하지만 SQL에서는 오히려 해당 상황을 지양하며 최대한 정규화하여 2개의 데이터를 분리한다.
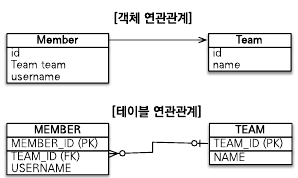
위 그림을 보면 OOP에서는 Team 타입의 필드를 그대로 가지고 있지만,
SQL에서는 데이터 중복을 줄이기 위해 Team_ID만 Member 테이블에 보관한다.
3. 객체 그래프 탐색
OOP에서는 자유로운 객체 그래프 탐색이 가능하다.
무슨 소리냐면 Member 객체가 Team 객체를 필드로 가지고 있고 Team 객체가 Product 객체를 가지고 있다고 가정하자.
그렇다면 다음과 같은 코드로 자유롭게 객체를 넘나들 수 있다.
member.getTeam().getProduct();하지만 SQL에서는 위와 같은 그래프 탐색에 제약이 있다.
SELECT M.*, T.* FROM MEMBER M, TEAM T
WHERE M.TEAM_ID = T.TEAM_ID;
-- 한 번 SQL 쿼리가 정해지면 Product로의 탐색이 불가.4. 비교
OOP에서는 같은 Value를 가지고 있다하더라도 객체가 저장된 주소가 다르다면 다른 객체로 취급된다.
하지만 SQL에서는 같은 Row는 여지없이 같은 데이터로 취급된다.
위와 같은 OOP와 SQL 사이의 괴리를 JPA에서 모두 해결해준다.
👣 JPA란 무엇일까
JPA는 기존의 JDBC로 다룰 때의 문제를 해결하기 위해 JDBC 위에 구현된 추상화 인터페이스다.
간단히 말하자면 JPA는 자바 진영 ORM 기술의 표준이다.

ORM이란 객체와 관계형 DB를 매핑하는 기술이다.
위에서 언급한 패러다임 불일치 문제를 개발자 대신 해결해준다.
JPA의 대표적인 구현체로는 Hibernate가 있다.
👣 JPA 사용 시, 유의점
1. ORM 프레임워크라 하더라도 SQL에 대한 이해는 필수다.
2. N+1 문제에 대해 각별한 주의가 필요하다.
3. 통계 쿼리처럼 복잡한 SQL에는 적합하지 못하다.
'JPA' 카테고리의 다른 글
| 5장 연관관계 매핑 기초 (0) | 2023.08.30 |
|---|---|
| 4장 엔티티 매핑 (0) | 2023.08.30 |
| 3장 영속성 관리 (0) | 2023.08.27 |
| 2장 JPA 시작 (0) | 2023.08.27 |
| '자바 ORM 표준 JPA 프로그래밍' 읽기 전략 (0) | 2023.08.24 |