👣 개요
자바 코드를 작성하고 해당 코드를 실행시키는 과정에 대해 작성하는 게시물이다.
👣 Java Compiler
자바 소스 코드(1)는 그 자체로 컴퓨터가 이해할 수 없기 때문에
컴퓨터가 이해할 수 있는 형식(2)으로 변환해야 한다.
// 자바 소스 파일(Swap.java) --- (1)
class Swap {
public static void main(String[] args) {
int[] testCase1 = {1, 26};
// swap : 배열의 특정 인덱스쌍의 위치를 바꾸는 함수.
swap(testCase1, 0, 1);
// 결과물 출력.
for (int item : testCase1) {
System.out.println(item);
}
}
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
}위 소스 코드는 [XXX.java]라는 확장자를 가지고 있으며
여기까지는 사람이 이해할 수 있는 언어로 되어 있다.
// 컴파일러로 변환된 바이트 코드(Swap.class) --- (2)
CA FE BA BE 00 00 00 34 00 12 0A 00 03 00 0F 09
00 10 00 11 08 00 12 07 00 13 07 00 14 01 00 06
3C 69 6E 69 74 3E 01 00 03 28 29 56 01 00 04 43
6F 64 65 01 00 0F 4C 69 6E 65 4E 75 6D 62 65 72
54 61 62 6C 65 01 00 0C 4C 6F 63 61 6C 56 61 72
69 61 62 6C 65 01 00 04 74 68 69 73 01 00 13 4C
48 65 6C 6C 6F 2C 20 57 6F 72 6C 64 21 01 00 06
...하지만 컴파일러로 변환을 하게 되면 다음과 같이
컴퓨터가 해석할 수 있는 16진수 형태로 표기가 된다.
해당 파일을 '바이트 코드'라고 하며 [XXX.class]라는 확장자를 가지게 된다.
참고로 해당 파일은 디컴파일러로 사람이 이해할 수 있는 언어로 변환할 수 있다.
# /bin/bash
javac {자바 소스 코드}.java이처럼 소스 코드를 바이트 코드로 해석해주는 것을 Java Compiler라고 한다.
👣 JVM 존재 이유
하지만 역시나 바이트 코드 자체로는 바로 프로그램을 실행할 수 없다.
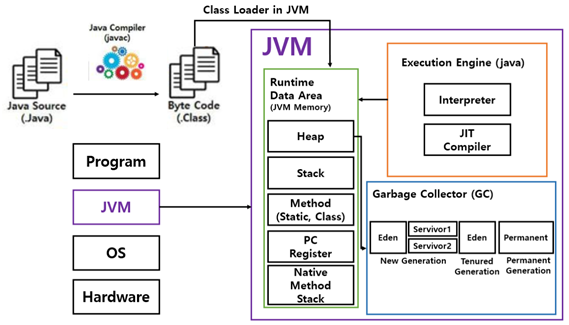
이것을 해석하고 실제로 실행시키는 프로그램을 JVM이라고 한다.
여기서 드는 의문은 굳이 바이트 코드라는 중간 단계를 거치는 이유가 무엇이냐 였다.
이것은 JAVA의 플랫폼 독립성을 위한 것이었고 OS가 다르다고 하여
각 OS마다 소스코드를 작성하는 것이 아닌 1개의 소스 코드로
각 OS의 JVM이 자기 방식대로 해석해 실행하기 때문이다.
👣 JVM 작동 방식
JVM은 다음과 같은 과정을 거친다.
- Class Loading
JVM은 실행할 클래스 파일을 찾아서 메모리로 로드한다.
이 과정에서 클래스 로더(Class Loader)가 사용되며,
필요한 클래스의 바이너리 형태인 바이트 코드를 읽어와 JVM 내부의 메모리로 로딩한다. - Interpretation
바이트 코드는 인터프리터에 의해 한 줄씩 해석된다. 인터프리터는 바이트 코드를 실행하면서 JVM의 가상 머신 명령어로 해석한다. 이는 바이트 코드를 직접 실행하는 방식이며, 인터프리터는 CPU에서 바로 실행할 수 있는 기계어로 변환하지 않고 JVM 명령어를 실행한다. - Just-In-Time Compilation
인터프리터와 함께 작동하여 프로그램의 실행 속도를 향상시킨다. 인터프리터가 반복적으로 실행되는 코드 영역을 감지하고, 해당 코드 영역을 컴파일하여 최적화된 기계어로 변환한다. 이렇게 변환된 기계어 코드는 캐시에 저장되어 다음에 해당 코드가 실행될 때 재사용한다. - Execution
최적화된 기계어로 변환된 코드는 JVM 내부의 실행 엔진에서 실행된다.
실행 엔진은 변환된 기계어 코드를 CPU에서 실행하여 프로그램의 동작을 실제로 수행한다.
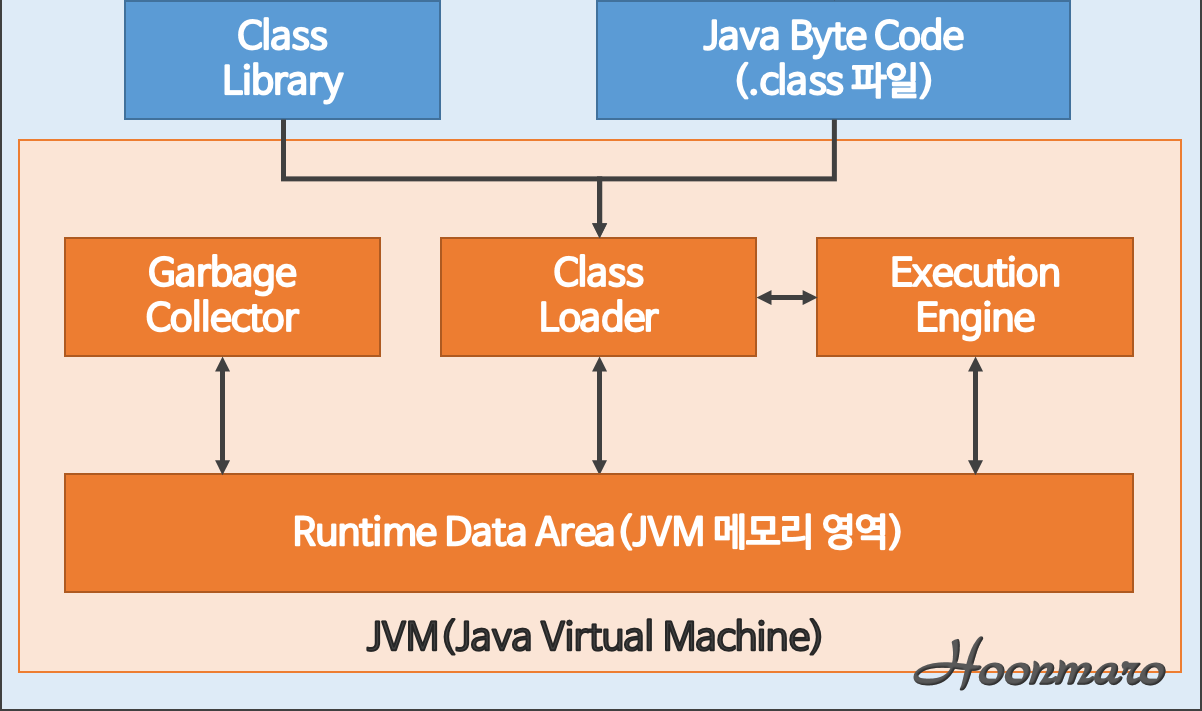
👣 Class Loader
컴파일한 바이트코드(*.class)를 실행시점(RunTime)에 읽어들여서
메모리(Runtime Data Area)에 적절하게 배치하는 것이 클래스로더의 역할이다.
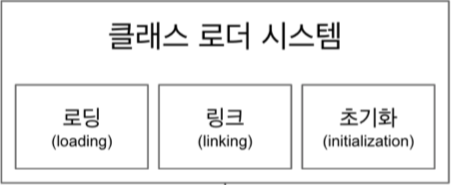
Class Loader는 3가지 순서로 실행된다.
- 로딩
클래스 로더가 바이트 코드를 읽고 그 내용에 따라 적절한 바이너리 데이터를 만들고 메서드 영역에 저장
로딩이 끝나면 해당 클래스 타입의 Class 객체를 생성하여 “힙" 영역에 저장. - 링크
Verify(확인), Prepare(준비), Resolve(해결) 세 단계로 나누어져 있다. - 초기화
static 변수의 값을 할당한다. static 블럭은 이때 실행된다
👣 Runtime Data Area
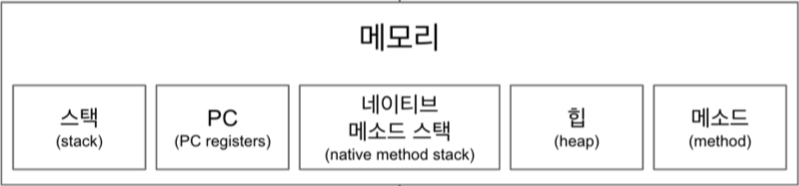
JVM이 프로그램을 실행하는 동안 사용되는 메모리 영역이다. 해당 영역은 5가지로 나뉜다.
- Method Area [전역 공유]
각 클래스의 정보[클래스 이름, 부모 클래스, ...]이 저장되며 정적 변수, 정적 메소드, 인스턴스 메소드가 저장되는 공간이다.
JVM이 종료될 때까지 메모리가 유지됨. - Heap [전역 공유]
동적으로 생성된 객체와 배열이 할당되는 영역. Gabage Collector에 의해 관리되는 영역. - Stack [Thread 내에서 공유]
메소드가 호출될 때마다 할당되는 메모리 영역으로 메소드 실행이 끝나면 다시 반납한다. 만약 지정된 크기 이상의 메모리가 할당되면 StackOverFlow 에러가 발생한다. - Program Counter Register [Thread 내에서 공유]
현재 실행 중인 JVM 명령어의 주소를 가리키는 포인터. - Native Method Stack [Thread 내에서 공유]
자바 언어 외부의 네이티브 코드(C, C++ 등)를 호출하는 메소드에 대한 정보를 저장하는 영역
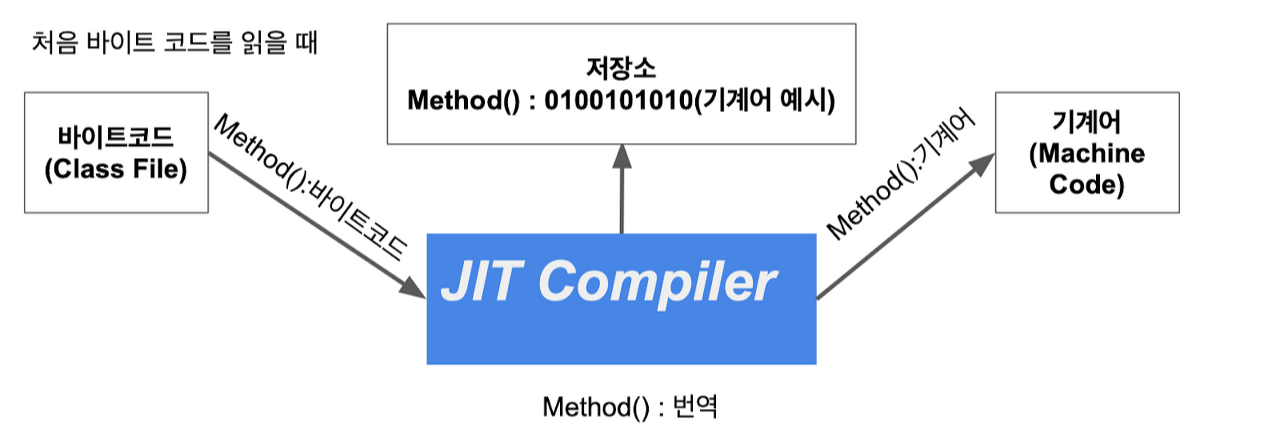
👣 JIT Compiler
최초의 JVM은 미리 컴파일해놓는 네이티브 언어에 비해 매우 느렸다.
하지만 JIT 도입을 통해 이러한 성능 차이를 줄일 수 있었다.
기존 JVM은 인터프리터 방식만 사용했다. 때문에 런타임 때마다 해석을 하며 실행했기에 속도가 느렸다.
JIT는 인터프리터가 반복적으로 해석하는 코드를 미리 실행 가능한 기계어로 번역해놓고 캐시에 저장한다.
때문에 다시 해석할 필요없이 저장소에서 바로 가져와 실행하기에 성능을 비약적으로 늘릴 수 있었다.
이는 네이티브 언어의 컴파일 방식을 차용했다고 볼 수 있다.
JVM는 인터프리터와 JIT를 상호 보완적으로 사용함으로써
인터프리터 방식과 컴파일 방식을 함께 사용한다고 볼 수 있다.

👣실제로 JVM을 사용하는 방법
결국, 실제로 JVM를 구동시키고 싶다면 다음과 같은 명령어를 실행하면 된다.
java {바이트 코드 파일}
# Ex) java Swap'Java' 카테고리의 다른 글
| Auto Boxing & Auto UnBoxing (0) | 2023.07.17 |
|---|---|
| 문자열 (0) | 2023.07.17 |
| Call By Value & Call By Reference (0) | 2023.07.17 |
| JDK, JRE, JVM (0) | 2023.07.17 |
| Garbage Collector (0) | 2023.07.17 |