👣 문답
7. JVM의 스택과 힙메모리 영역에 대해 아는 만큼 설명해주실 수 있을까요?
my)
JVM은 프로그램 중 필요한 메모리들을 관리해주는 역할을 가지고 있습니다.
JVM이 관리하는 메모리를 영역을 'Runtime Data Area'라고 부르는데
메모리 영역 중
함수를 실행하기 위해 지역 변수를 저장하는 공간을 '스택'이라고 부르며
배열 혹은 참조형 변수를 저장하는 공간을 '힙메모리 영역'이라고 부릅니다.
'스택'은 이름 그대로 Stack 자료 구조를 가지고 있으며, 함수가 시작될 때마다
Stack에 Stack Frame이 하나씩 쌓이며 함수가 종료되면 해당 Stack Frame을 Pop시킵니다.
이러한 구조로 인해 굳이 Garbage Collector가 직접 메모리 정리를 하지 않아도 된다는 장점이 있습니다.
또한 재귀함수를 무한히 호출하다보면 StackOverFlow 예외가 발생하게 되는데 이는
설정된 Stack 크기 이상으로 Stack Frame이 쌓이기 때문에 발생하는 현상입니다.
'힙메모리 영역'은 모든 Thread에서 공유되는 자원으로 참조형 변수값을 저장하는 공간입니다.
해당 공간은 함수가 종료되어도 삭제되지 않는 특징을 가지고 있습니다.
다만, 만약 해당 메모리 주소를 참조하는 곳이 1곳도 존재하지 않게 된다면
Garbage Collector에 의해 메모리 정리가 됩니다. 만약 불필요한 메모리를 많이 생성하게 되면
차후 Garbage Collector가 처리해야 할 메모리 공간이 많아지게 되고
성능 하락으로 이어지기 때문에 가능하다면 Singleton 패턴으로 인스턴스를 만드는 것이 좋습니다.
Java에서 new 연산자로 해당 영역에 메모리를 할당할 수 있습니다.
8. 클래스와 인스턴스의 차이에 대해 설명해주실 수 있을까요?
my)
"인스턴스"는 실제로 프로그램을 수행할 때, 사용되는 데이터를 의미합니다.
이러한 데이터는 의미 단위로 몇몇 개의 변수들을 포함하고 있으며,
몇몇 개의 메서드를 같이 저장하고 있습니다.
이러한 데이터의 구조를 정의내리는 곳이 바로 '클래스'입니다.
쉽게 말해 인스턴스의 구조를 정의내리는 곳이 '클래스'이고
해당 클래스 명세에 맞춰 만들어진 실제 데이터를 '인스턴스'라고 합니다.
9. Garbage Collector의 역할, 원리, 알고리즘에 대해 아는 만큼 설명해주실 수 있을까요?
my)
Garbage Collector는 JVM에 존재하는 것들 중 하나로서 Heap Area의 메모리를 정리하는 역할을 맡고 있습니다.
GC의 제거 대상은 참조 대상이 더 이상 존재하지 않는 Heap Area 메모리들입니다.
GC는 'Mark and Sweep'라는 방법으로 메모리를 삭제합니다.
Mark and Sweep은 3가지 단계로 이뤄집니다.
첫 번째 Mark 단계는 Root Space부터 그래프 순회를 통해 참조되고 있는 메모리들을 찾아냅니다.
이 때, 다른 Thread에 의해 Mark되지 않았지만 참조되고 있는 메모리가 발생하는 것을 막기 위해
Stop-The-World를 수행합니다.
두 번째 Sweep 단계는 Marking된 메모리를 제외한 나머지 모든 메모리를 제거하는 단계입니다.
세 번째는 Compact 단계로서 제거된 메모리에 의해 발생한 빈 메모리 공간을 제거하기 위해
다시 차곡차곡 메모리를 재정립하는 단계입니다.
Heap Area는 애초에 '약한 세대 가설'에 의거해 설계가 되어 young generation과 old generation으로 나뉘는데
만약 특정 공간 속에 할당할 메모리가 더 이상 존재하지 않는다면 해당 공간에 대해 'Mark and Sweep'을 수행하게 됩니다.
10.Java Map의 내부 구현은 어떻게 이루어져 있을지 추측해보실 수 있을까요?
my)
Java Map의 구현체의 구현 방법에 대해 여쭤보는 것으로 이해하고 말씀을 드리겠습니다.
Map은 Key값과 함께 Value 데이터를 저장하는 클래스로서 Key값을 이용한다면
Value를 검색할 수 있다는 특징을 가지고 있습니다.
제가 알고 있는 대표적인 구현체는 크게 2가지가 있습니다.
첫 번째로는 TreeMap으로서 이진 트리 구조를 이용해 데이터들을 저장하고
조회 시 Log 시간 수준의 시간동안 검색하게 됩니다.
두 번째로는 HashMap으로서 해시 테이블 구조를 이용해 데이터를 저장하고
조회 시 상수 시간 수준의 시간동안 검색하게 됩니다.
두 자료구조 모두 요소 사이의 크기 비교가 가능해야 한다는 특징을 가지고 있으며
내부적으로 이것을 해결하기 위해 Comparable 혹은 Comporator 인터페이스를
사용하고 있다고 알고 있습니다.
11.DI와 IoC에 대해 아는 만큼 설명해주실 수 있을까요?
my)
DI와 IoC는 각각 Dependency Injection, Inversion of Control라는 뜻으로서
Spring Framework의 Bean Container로 인해 누릴 수 있는 이점들입니다.
Spring Framework에서는 구현체를 사용하기 위해 소스 코드에 직접
구현체명을 명시하지 않고 단순히 해당 구현체를 Bean Container에 보관하기만 하며
Spring이 알아서 Bean을 조립해줍니다. 이것을 통해 개발자는 각 클래스 사이의
의존도를 크게 낮출 수 있기에 유지 보수성이 크게 향상됩니다.
결론적으로 DI는 Bean을 생성할 때, 필요한 의존성을 주입해준다는 것을 의미하고
IoC는 Bean의 의존성 주입에 대한 제어권을 개발자가 아닌 Spring이 가진다는 의미에서
'제어권의 역전' 즉, Inversion of Control을 의미합니다.
12. MVC 모델이란 무엇인지 설명해주실 수 있을까요?
my)
MVC 모델은 Spring Framework에서 사용되는 디자인 패턴입니다.
MVC 각각은 Model, View, Controller의 앞글자를 따온 것으로
Model은 실제로 요청을 처리해 응답을 위한 데이터를 생산하는 비즈니스 코드가 작성되는 곳을 의미하고
View는 Model에서 처리된 데이터를 사용자에게 Html 형식으로 보여주기 위해 UI를 작성하는 곳을 의미하고
Controller는 Model과 View를 중계해주는 징검다리 역할을 수행하는 곳을 의미합니다.
이 3가지 부분을 나누어 관리를 함으로서 각 역할 사이의 의존성을 크게 줄이며
유지 보수성을 향상시킬 수 있습니다. 데이터를 교체할 필요없이 단순히 Html 부분만 교정하고 싶다면
View 부분만 수정하면 되고 데이터를 생산, 가공하는 방식을 바꾸고 싶다면 Model 부분만 수정하면 됩니다.
이러한 것을 보아 유지보수성이 크게 증가함을 알 수 있습니다.
13. Annotation이란 무엇이고 구체적으로 어떤 것이 있는지 예시를 들어 설명해주실 수 있을까요?
my)
Annotation은 클래스, 메서드, 파라미터, 필드 등등에 특별한 표식을 남기기 위해 사용하는 것으로
그 자체로는 특별한 기능은 없습니다. 하지만 Reflection을 이용하면 특정 Annotation이 남겨진 클래스, 메서드, 파라미터, 필드 등등에 값을 주입한다던지 기록을 남긴다던지 등등의 업무를 수행할 수 있습니다.
구체적인 예시를 들어보자면, @Autowired라는 어노테이션이 존재하는데 해당 어노테이션이 필드에 붙는다면,
Bean Container가 해당 필드의 타입에 부합하는 Bean을 찾아서 주입해줍니다.
뿐만 아니라 @Component라는 어노테이션도 존재하는데 해당 어노테이션이 붙은 클래스들은
역시나 Bean Container 안에 담기게 됩니다. 이처럼 Annotation으로 표식을 남길 수 있고
특수한 프로세서에 의해 특정 업무를 처리할 수 있습니다.
14. Spring Security의 구조와 JWT 발급 과정에 대해 설명해주실 수 있을까요?
my)
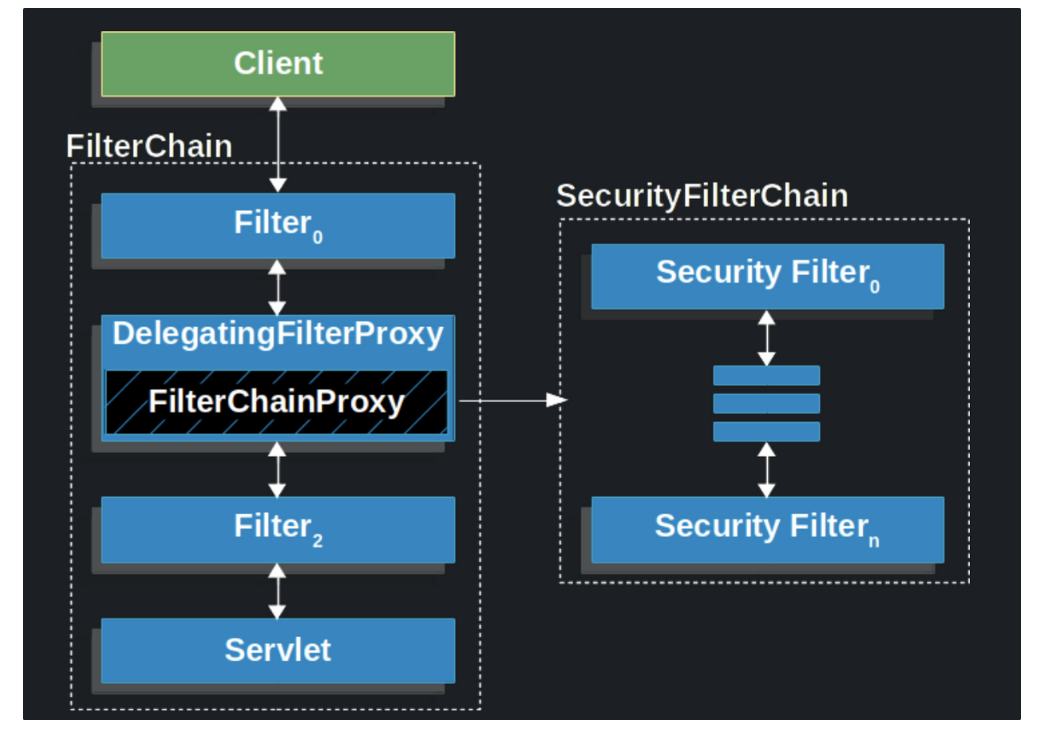
Spring Security의 구조는 필터 뭉치로 이뤄져 있다고 말할 수 있습니다.
Spring security의 필터들은 DelegatingFilterProxy 내부에 존재하기 때문에
각각의 필터는 Bean으로 구성될 수 있습니다.
해당 필터들을 SecurityFilterChain라고 부르고 각자 다양한 기능을 수행합니다.
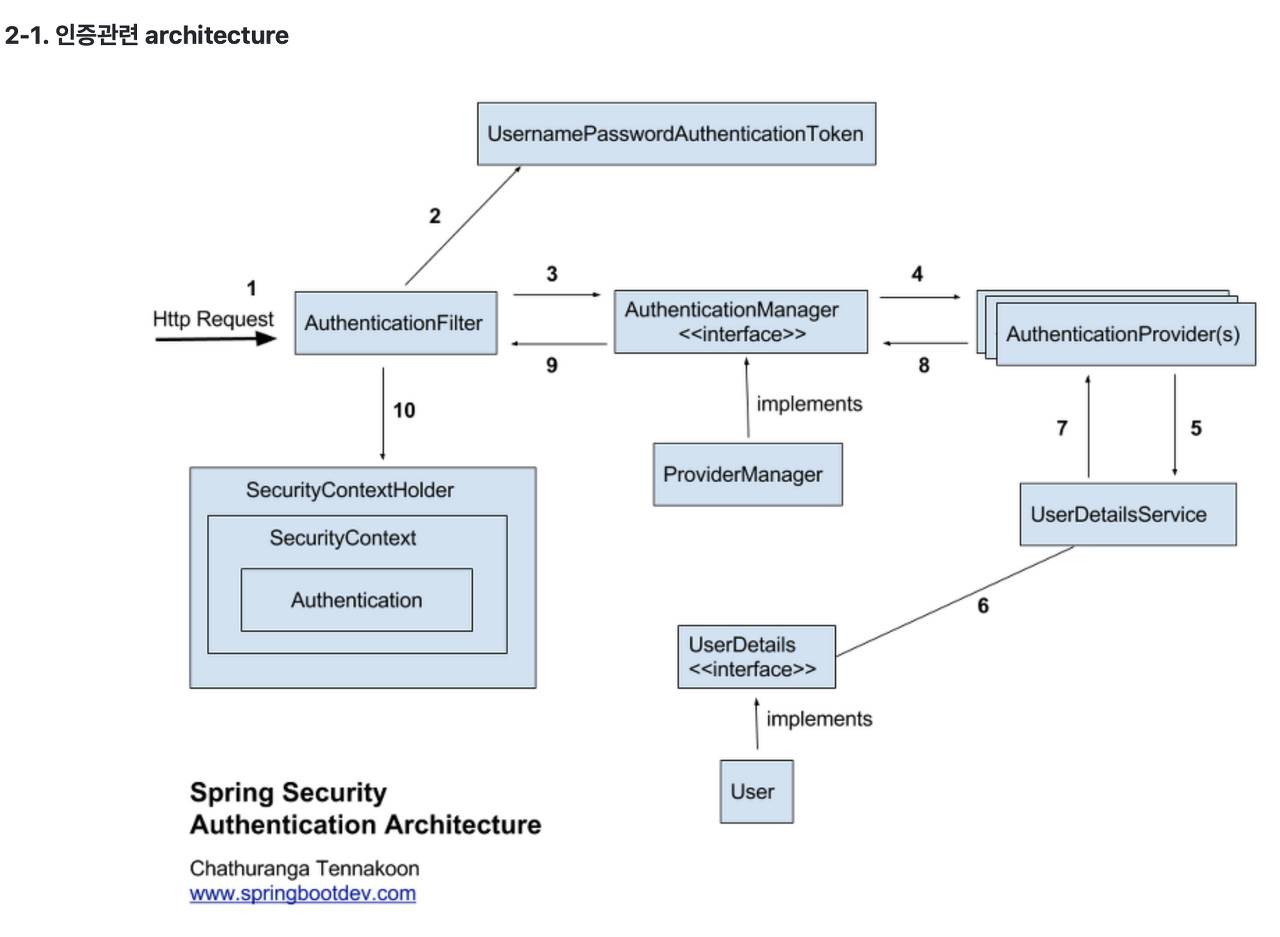
Spring Security에서의 JWT 발급 과정은 구현체에 따라 달라질 수도 있겠지만
대략적인 발급 과정은 3 부분으로 나뉠 수 있습니다.
첫 번째는 인증 정보를 이용한 검증 과정,
두 번째는 검증 이후 JWT 토큰 생성 과정,
세 번째는 JWT 토큰를 응답에 싣는 과정으로 볼 수 있습니다.
첫 번째 과정은 ID, Password 혹은 소셜 로그인 등등의 방법으로 구현될 수 있고
두 번째 과정은 마찬가지로 Claim 정보를 Base64로 암호화 후,
비밀키 혹은 대칭키 등등으로 암호화하는 방법으로 구현될 수 있으며,
세 번째 과정은 헤더, 쿠키, Json 등등의 방법으로 전달될 수 있습니다.
위 과정은 Spring Security의 SecurityFilterChain의 하나의 필터로 구현할 수도 있습니다.
[Spring Security] 공식 문서로 Spring Security 구조 파악하기
스프링 시큐리티 Spring Security Spring Security는 Spring기반 애플리케이션을 보호하기 위한 표준으로 직접 커스텀이 가능한 인증 및 Access Control 프레임워크이다. 이는 Java 애플리케이션에 인증과 인가(
loosie.tistory.com
15. N+1 문제의 발생 이유와 해결 방법에 대해 설명해주실 수 있을까요? 해결 방법은 3가지 이상 말씀해주시면 좋습니다.
my)
N+1 문제는 JPA의 지연 로딩으로 인해 1번의 쿼리로 끝날 연산을 일대다 연관 관계에 의해
N+1개의 쿼리를 호출하는 것을 의미합니다.
예를 들어, 게시판 페이지를 구성하기 위해 1개의 게시글과 n개의 댓글이 로드되어야 한다고 가정 시,
Join 연산을 이용한다면 1개의 게시글에 딸린 댓글들 모두 가져올 수 있기에 1개의 쿼리로도 충족할 수 있습니다.
하지만 JPA에서 지연 로딩을 사용한다면 런타임 당시에 필요한 정보를 그때그때마다 호출하므로
1개의 게시글을 불러오고 해당 게시글이 요구하는 댓글을 1개씩 개별적인 쿼리로 불러오게 됩니다.
결국, 이것을 해결하기 위해선 지연 로딩으로 인한 원인을 제거하면 됩니다.
첫 번째 방법은 글로벌 Fetch 전략을 모투 Eager로 바꾸면 됩니다.
애초에 기본값을 연관 관계를 호출할 때, 모든 하위 엔티티를 가져오게 하면 N+1문제는 해결 가능합니다.
두 번째 방법은 JPQL을 이용해서 단순 Join 연산이 아닌 Fetch Join을 수행하는 것 입니다.
Fetch Join 연산은 SQL Join처럼 아예 모든 테이블을 로드 후 취합한 상태에서 게산하게 해주기 때문에
N+1문제를 해결해줍니다.
세 번째 방법은 엔티티 그래프를 이용하는 것 입니다.
엔티티 그래프를 이용하면 굳이 쿼리를 작성하지 않고 단순히 Fetch Join하고 싶은 속성명만 명시하면
엔티티 호출 당시 자동으로 연관 관계의 엔티티들을 가지고 옵니다.
네 번째 방법은 Batch Size를 설정하는 것 입니다.
JPA는 IN 연산자를 이용해서 Batch Size 만큼 모아뒀다가 한꺼번에 쿼리를 내보낼 수 있습니다.
이러한 방법들을 이용하면 N+1 문제를 해결할 수 있습니다.
16. 즉시로딩과 지연로딩은 각각 언제 사용하면 좋은지 설명해주실 수 있을까요?
my)
즉시로딩은 연관 관계의 엔티티를 1개의 쿼리로 모두 가지고 오는 것을 의미하며
지연로딩은 연관 관계의 엔티티를 런타임 당시 필요할 때 그때그때마다 가지고 오는 것을 의미합니다.
즉시로딩의 경우, 특정 연관 관계의 엔티티가 확정적으로 가져올 것이 예측될 때,
쿼리를 절약할 수 있다는 장점이 있습니다. 하지만 이것을 남용하게 되면 사용하지도 않는 정보에
연산을 낭비하는 경우가 발생할 수 있습니다.
지연로딩의 경우, 하나의 코드로 다양한 엔티티 조합을 불러올 수 있다는 장점도 있고
사용하지 않을 정보를 위해 연산을 낭비하지 않는다는 장점이 있습니다.
하지만 이 경우, N+1 문제를 야기할 수 있습니다.
17. Spring bean container 생성부터 스프링 종료까지의 사이클에 대해 알려주실 수 있을까요?
@PostConstruct, @PreDestroy 어노테이션의 역할도 함께 알려주시면 좋습니다.
Spring Bean의 Life Cycle은 총 8 단계로 나눠서 설명 가능합니다.
'IoC Container 생성', 'Bean 등록', '의존관계 주입', '@PostConstruct 메서드 수행'
'Bean 사용'
'@PreDestroy 메서드 수행', 'IoC container 종료' 순으로 진행이 됩니다.
@PostConstruct는 Bean의 의존관계 주입이 끝난 후의 작업을 지정할 때, 사용할 수 있습니다.
주로 Bean 사용을 위한 자원을 생성하기 위해 사용됩니다.
@PreDestroy는 Bean 소멸 전에 수행할 작업을 지정할 때, 사용할 수 있습니다.
주로 자원 정리를 위해 사용합니다.
18. AOP, Interceptor, Filter 의 차이점, Request가 들어올때 거치는 순서, 각 역할들의 장점을 설명해주실 수 있을까요?
AOP, Interceptor, Filter 모두 프록시 패턴을 이용해 특정 작업을 수행하기 전후에
공통적인 보안 처리, 트랜잭션 처리, 로깅 등등을 수행할 수 있게 도와주는 도구들입니다.
하지만 각각은 작동하는 위치가 모두 다릅니다.
Filter 의 경우, Dispatcher Servlet 외부에서 작동하는 프록시 입니다.
Spring Framework에 종속되지 않고 Servlet 스펙에 종속되어 있다는 특징이 있습니다.
Filter는 모든 요청과 응답에 예외없이 적용됩니다. 때문에 누락없이 적용해야 하는 작업에 유리합니다.
Interceptor 의 경우, Dispatcher Servlet 내부와 Controller 외부에서 작동하는 프록시 입니다.
Filter와 달리, Spring Framework에 종속된 기술이며, 특정 URL의 요청에만 반응할 수 있습니다.
Bean Container의 Bean들을 사용할 수 있습니다.
AOP 의 경우, 비즈니스 로직에서도 사용할 수 있는 프록시 입니다.
Interceptor와 달리 특정 URL에만 작동하는 것 외에도 특정 메서드, 특정 파라미터, 특정 Annotation을
트리거 삼아 작동할 수 있습니다. 때문에 세밀한 로직 적용이 가능하다는 특징이 있습니다.
Request가 처리될 때 마주치는 순서는 Filter, Interceptor, AOP 순으로 마주치게 됩니다.
각각의 장점은 Filter, Interceptor, AOP 순으로
'누락없이 모든 요청에 적용이 가능하다.',
'특정 URL에 대해서만 적용이 가능하다.',
'비즈니스 로직에서도 적용 가능하다.'라는 장점들이 있습니다.

19. NoSQL과 RDBMS의 특징과 차이점에 대해서 장, 단점을 들어 설명해주세요.
my)
RDBMS는 관계형 데이터베이스를 사용하기 위한 프로그램들로서
데이터의 중복을 크게 줄일 수 있어서 삭제 이상, 수정 이상, 삽입 이상에 강합니다.
NoSQL은 RDBMS와 달리 일정한 스키마가 존재하지 않아 각 튜플을 구분지을 수 있는 Key값만 주어진다면
어떤 튜플이든지 저장할 수 있습니다. NoSQL은 Json, XML, Key-Value 등등의 형식으로 저장할 수 있으며
스키마로부터 자유롭기 때문에 수평적 확장이 편합니다.
RDBMS의 장점은 데이터 무결성을 준수하기 편하다라는 장점이 있습니다.
예를 들어, 거래 데이터와 연관 관계에 있는 회원 데이터를 수정하면,
다른 데이터들와 연관 관계에 있는 상품 데이터들에 대해 전역적으로 수정됩니다.
뿐만 아니라 다른 프로그램이라도 SQL라는 언어를 공통적으로 사용하고 있기에
일부 함수를 제외하면 거의 그대로 적용할 수 있습니다.
RDBMS의 단점은 조회 속도가 NoSQL에 비해 비교적 느린 편입니다.
테이블들이 조각조각 나뉘어져 있기 때문에 조회 시, Join 연산을 추가로 수행해야 하기에 조회속도가 느립니다.
뿐만 아니라 테이블 사이의 관계를 고려해야 하기 때문에 서버의 확장이 어렵습니다.
NoSQL의 장점은 수평적 확장이 쉽다는 것입니다. 관계성을 고려하지 않고 단순히 데이터를 적재하면 되기에
DB 속의 데이터를 다른 서버로 옮기면 쉽게 서버를 확장할 수 있습니다.
뿐만 아니라 조회 시, Join 연산과 같은 부차적인 연산을 하지 않아도 되기에
조회 속도도 비교적 빠른 편입니다.
NoSQL의 단점은 데이터 무결성을 지키기 어렵다는 것입니다.
거래 데이터 속 회원 데이터를 수정하면, 댓글 데이터 속 회원 데이터와 값이 달라질 수 있기에
동일한 데이터를 확보하기 어려울 수 있습니다.
뿐만 아니라 일부 NoSQL 프로그램은 복잡한 쿼리를 이용해 검색하기가 어려울 수 있습니다.
20. mvc 패턴에 대해서 설명해주세요.
my)
MVC 패턴은 Spring Framework에서 적극적으로 사용하고 있는 디자인 패턴입니다.
각각의 요청에 대해 1개의 Servlet을 할당했던 기존의 아키텍처에서
각 요청에 대해 1개의 DispatcherServlet을 이용해 요청에 걸맞는 Controller로 보내고
Controller는 Model을 이용해 적절한 데이터를 생산하고 Model에서 생산한 데이터를
View에 얹어 응답을 출력하는 형태로 이뤄져 있습니다.
MVC에 각각에 대해 좀더 자세히 설명하자면
M은 Model의 줄임말로서 요청에서 요구한 데이터를 생산하는 비즈니스 코드가 존재하는 곳입니다.
DB에서 데이터를 가져온 뒤, 출력 형식에 맞게 가공하는 역할을 수행합니다.
V는 View의 줄임말로 UI를 위한 HTML 템플릿을 의미합니다. 해당 템플릿에 Model이 생산한 데이터를
대입해주면 사용자가 원하는 웹 페이지 화면을 만들 수 있습니다.
C는 Controller의 줄임말로 사용자의 요청의 URL 패턴에 따라 적절한 Controller가 작동하며
Model과 View를 이용해 응답 생성과정을 통제하는 역할을 맡고 있습니다.
MVC 를 각각 분리함으로서 각 Component는 독립성을 가지고 유지 보수성을 크게 늘릴 수 있습니다.
뿐만 아니라 잘 설계된 Component의 경우, 다른 프로그램에서도 재사용될 수도 있으며
분리가 잘되어 있다면 테스트도 굉장히 용이해 집니다.
'취업 관련 준비' 카테고리의 다른 글
| 기술 면접 대비 예상 질문 모음 - 11/14 ~ 11/17 (0) | 2023.11.17 |
|---|---|
| 기술 면접 대비 예상 질문 모음 - 10/30 ~ 11/3 (0) | 2023.11.02 |
| 기술 면접 대비 예상 질문 모음 - 10/23 ~ 10/27 (0) | 2023.10.27 |