👣 개요
인덱스는 보통 B-트리로 구성되어 특정 값에 대한 조회가 O(log n) 복잡도로 수행된다.
만약 인덱스가 존재하지 않는 칼럼을 이용해서 조회를 하면 O(n) 복잡도로 , 즉 선형 탐색으로 검색을 수행할 것이다.
인덱스가 존재한다면 조회 성능은 비약적으로 좋아질 것이다.
하지만, 인덱스를 위한 추가적인 저장 공간을 필요로 할 뿐만 아니라
생성, 수정, 삭제를 위해 인덱스에 추가 연산을 수행해야 한다는 점으로 인해 생성, 수정, 삭제 성능은 악화된다.
👣 인덱스 생성 방법
👣 MySQL
1. 클러스터형 인덱스
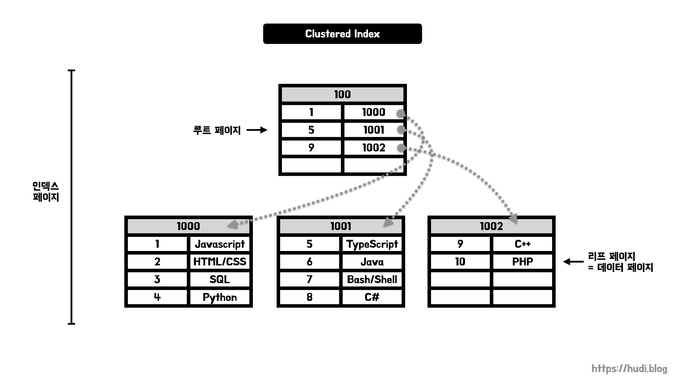
클러스터형 인덱스는 인덱스와 실제 데이터 레코드를 동일한 페이지에 저장함.
쉽게 말해서 B+Tree 구조로 클러스터형 인덱스를 구성할 때,
리프 노드에 '레코드의 PK 값'이 아니라 '레코드의 실제 주소값'을 넣는다는 것이다.
InnoDB 테이블은 기본 키에 대해서만 클러스터형 인덱스를 지원한다.
기본 키가 없는 경우에는 InnoDB는 임의의 고유 식별자를 생성하여 클러스터형 인덱스로 사용한다.
-- 해당 쿼리는 클러스터형 인덱스만 사용함.
SELECT * FROM AGENT WHERE {기본 키 필드} = 3;2. 세컨더리 인덱스
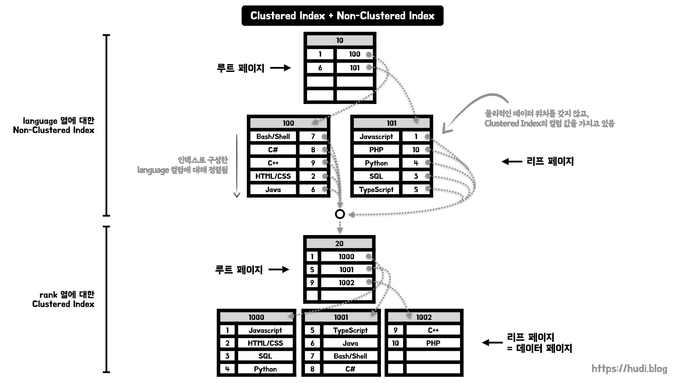
세컨더리 인덱스는 기본 키 이외의 Column을 이용해서 데이터를 검색하는 인덱스.
쉽게 말해서 B+Tree 구조로 세컨더리 인덱스를 구성할 때,
리프 노드에 '레코드의 PK 값'을 넣는다는 것이다.
해당 방식은 '레코드의 PK 값'만 구할 수 있기 때문에
필요하다면 추가로 클러스터형 인덱스를 사용해야 한다.
CREATE INDEX idx_agent_name ON AGENT (name);
-- 해당 쿼리는 클러스터형 인덱스와 세컨더리 인덱스를 사용함.
SELECT * FROM AGENT WHERE name = '김철수';👣 MongoDB
도큐먼트를 만들면 자동으로 ObjectID가 생성되고 해당 값이 기본키로 설정된다.
해당 값으로 B-tree를 생성한다.
MongoDB 역시 부가적으로 설정하면 세컨더리 키로 B-tree를 구성해 조회 성능을 높일 수 있다.
👣 복합 인덱스
인덱스는 칼럼 1개 이상으로 구성될 수도 있다.
다만 이 때, 칼럼의 순서에 주의해야 한다.
예를 들어, {name, age}로 정렬한 인덱스와 {age, name}으로 정렬한 인덱스는 다른 인덱스라는 것이다.
{name, age}로 B-tree에 데이터를 정렬할 때, name을 우선 순위로 정렬을 수행하다가
같은 name의 데이터가 존재한다면 age를 이용해서 마저 정렬을 진행하는 것이다.
때문에 인덱스의 순서는 성능에 영향을 줄 수 있어서 신중해야 한다.