B-tree 역시 'AVL 트리'와 '레드 블랙 트리'와 같이 Balanced Tree이다. 다만 균형 이진 탐색 트리는 아니다.
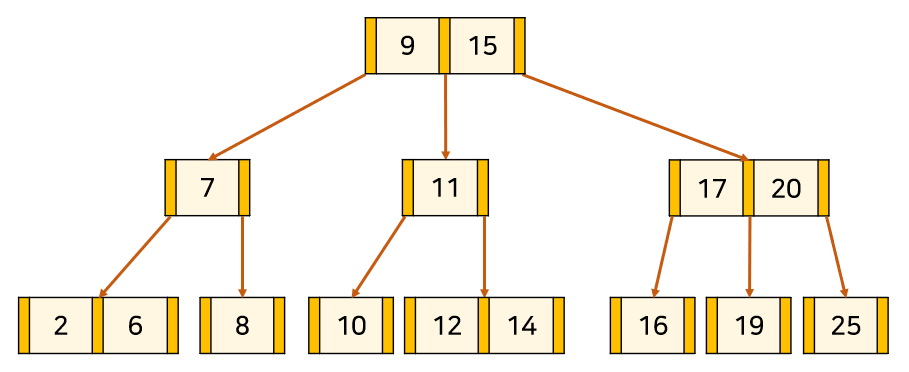
B-tree는 앞서 살펴봤던 트리들과는 달리 Node당 1 개 이상의 데이터가 포함된다.
Node 안은 여러 개의 Key로 이뤄져 있다.
그리고 B-tree는 차수라는 속성을 가지고 있다. 이는 한 Node의 최대 자식 Node 갯수를 의미한다.
B-tree는 높이를 최소화하기 위해 노드의 분할과 병합을 수행한다.
주로 DB의 인덱스를 구현하기 위해 사용되는 자료 구조다.
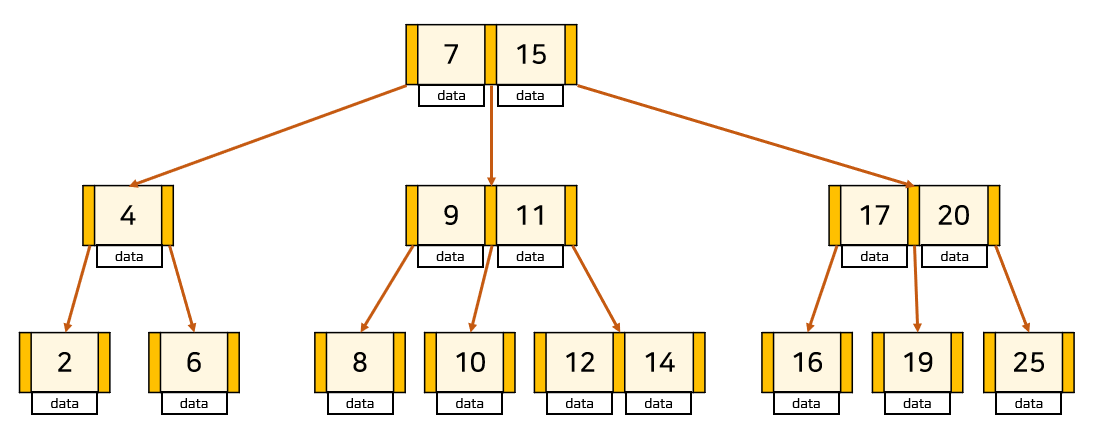
👣 B-tree 조건
1. node의 key의 수가 k개라면, 자식 node의 수는 k+1개이다. ["Key 갯수" + 1 = "자식 Node 수"]
2. node의 key는 오름차순으로 정렬된 상태여야 한다.
3. root node는 항상 1개 이상의 Key를 갖는다. (root node가 leaf node인 경우 제외)
4. M차 트리일 때, root node와 leaf node를 제외한 모든 node는최소 ⌈M/2⌉개, 최대 M개의 서브 트리를 갖는다.
M/2 이하 갯수면 병합을, M개 이상이면 분할이 이뤄진다.
5. 모든 leaf node들은 같은 level에 있어야 한다.
👣 B-tree 탐색
1) root node부터 탐색을 시작한다.
2) node의 key를 순회하여 K가 존재하면 탐색을 종료한다.
3) k가 존재하지 않는다면, 어떤 이웃한 두 key 사이에 K가 들어가는 경우 사이의 포인터를 통해 자식 node로 내려간다.
4) leaf node까지 2~3을 반복한다.
만약 차수 값이 너무 커서 한 Node에 너무 많은 Key가 존재한다면
한 노드 내에 Binary Search[이분 탐색]으로 탐색할 수 있다. [정렬된 상태이기 때문에 가능.]
👣 B-tree 삽입
삽입은 크게 2 개의 Part로 구성되어 있다.
1. 우선 탐색과 같은 방식으로 삽입.
2. 'B-tree 조건'에 맞게 노드 분할.
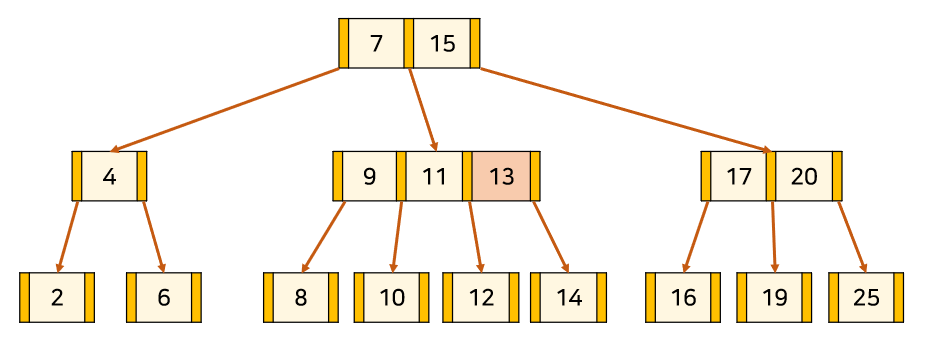
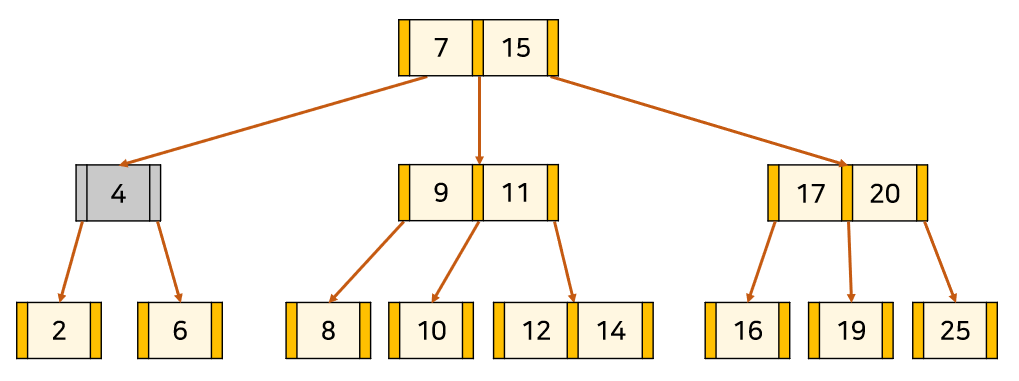
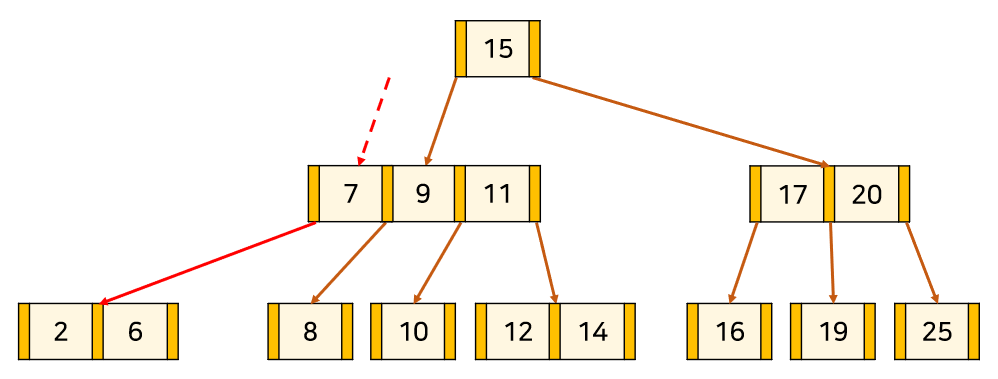
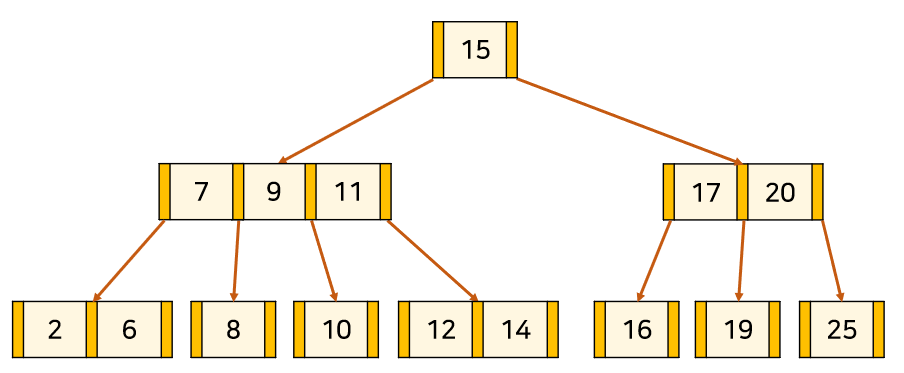
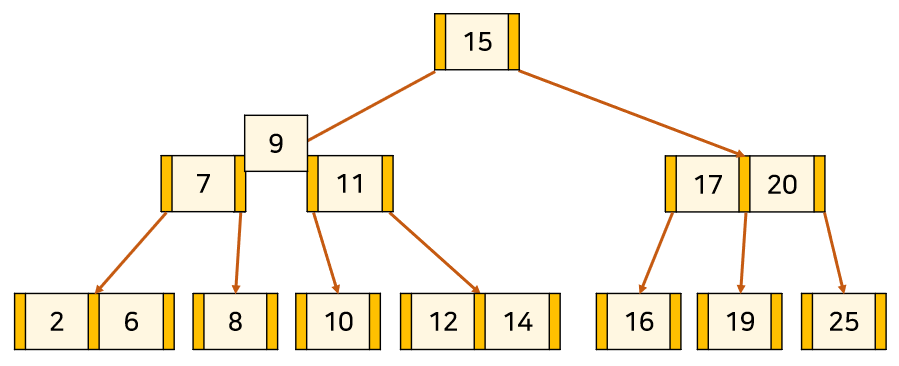
아래 예시는 3차 B-tree에 13을 삽입하는 예시다.
1. 'B-tree 탐색'과 같은 방식으로 노드 삽입 위치를 찾고 넣는다.
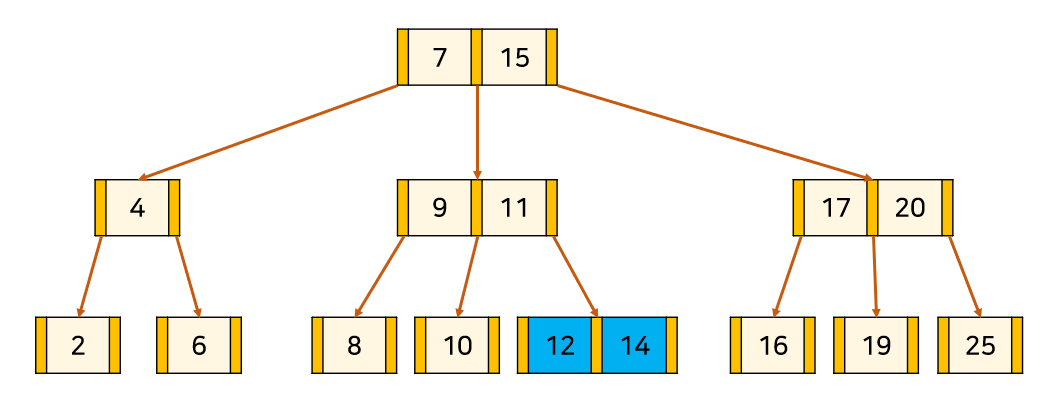

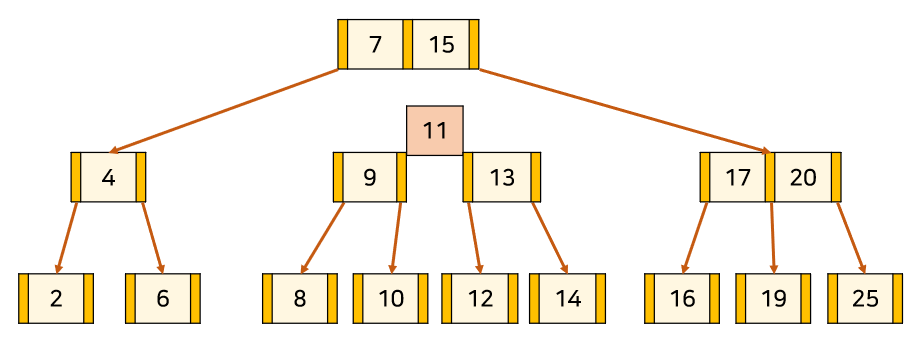
2. Node를 분할을 하되 포화 상태의 Node의 중앙값[13]을 기준으로
좌측을 중앙값의 왼쪽 자식 서브트리[12], 우측을 중앙값의 오른쪽 자식 서브트리[14] 취급한다.
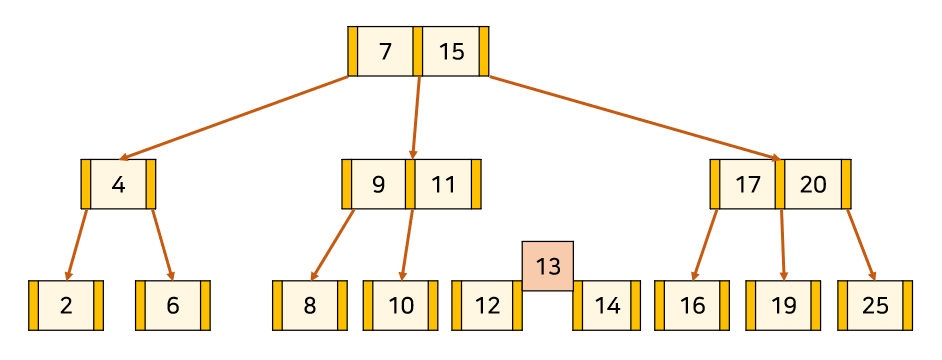
3. 만약 분할로 인해 상위 Node가 또 포화상태가 되면 재귀적으로 분할을 시도한다.

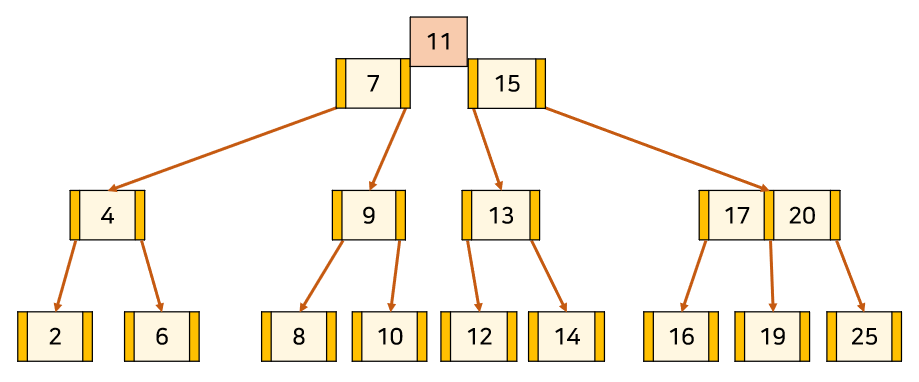
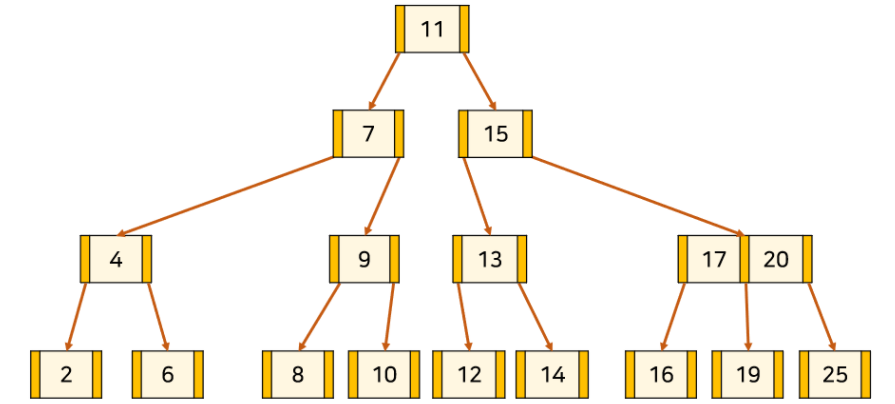
👣 B-tree 삭제
삭제 과정은 굉장히 복잡해 경우를 나누어 설명해야 한다.
1. 삭제 대상이 Leaf Node인 경우
- 삭제 대상이 속한 Node 갯수가 [M/2 <] 인 경우
- 삭제 대상이 속한 Node 갯수가 [M/2 ==] 인 경우 && 형제 Node가 [M/2 <] 인 경우
- 삭제 대상이 속한 Node 갯수가 [M/2 ==] 인 경우 && 형제 Node가 [M/2 ==] 인 경우 && 부모 Node가 [M/2 <] 인 경우
- 삭제 대상이 속한 Node 갯수가 [M/2 ==] 인 경우 && 형제 Node가 [M/2 ==] 인 경우 && 부모 Node가 [M/2 ==] 인 경우
2. 삭제 대상이 Leaf Node가 아닌 경우
- 삭제 대상이 속한 Node 갯수가 [M/2 <] 인 경우 || 자식 Node 갯수가 [M/2 <] 인 경우
- 삭제 대상이 속한 Node 갯수가 [M/2 ==] 인 경우 && 자식 Node 갯수가 [M/2 ==] 인 경우
다음은 구체적인 삭제 과정이다.
삭제하기에 앞서서 자주 사용되는 용어를 약어로 정의하고 설명해야 합니다.
| 약어 | 설명 |
| Max Key in Left | 현재 node의 왼쪽 자손 중 가장 큰 key |
| Min Key in Right | 현재 node의 오른쪽 자손 중 가장 작은 key |
| Eldest Uncle Key | 부모 node의 포인터의 오른쪽에 있는 key. 가장 우측에 있는 포인터인 경우 왼쪽에 있는 key. |
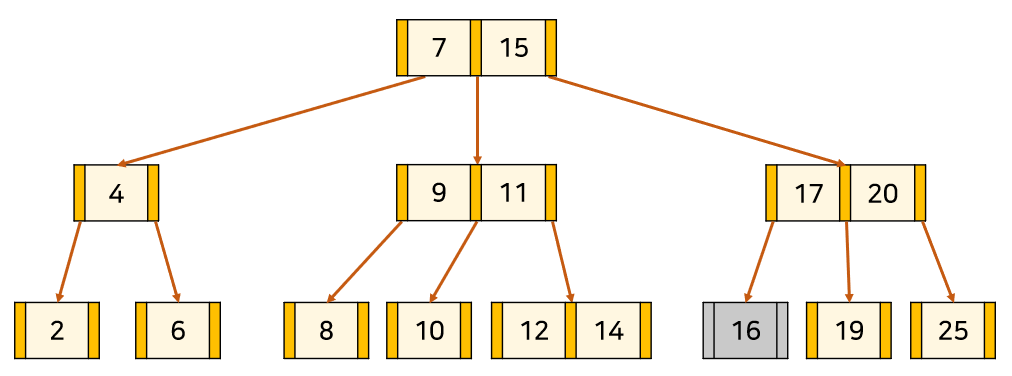
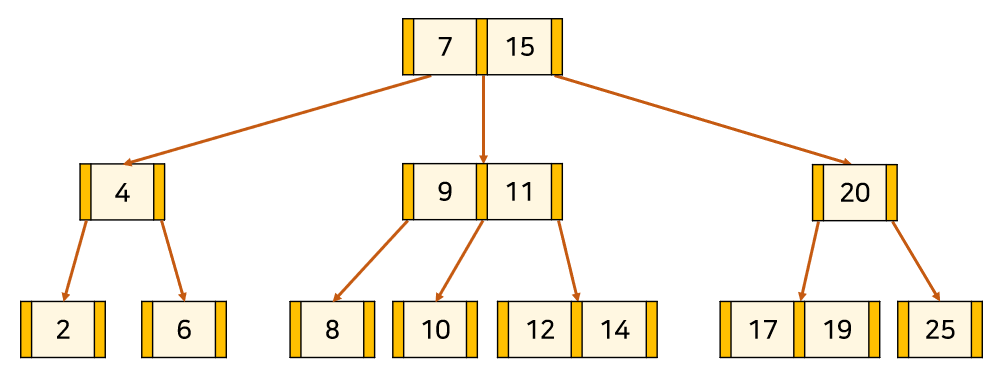
(1-1) 경우
1. 쿨하게 그냥 삭제하면 됨.
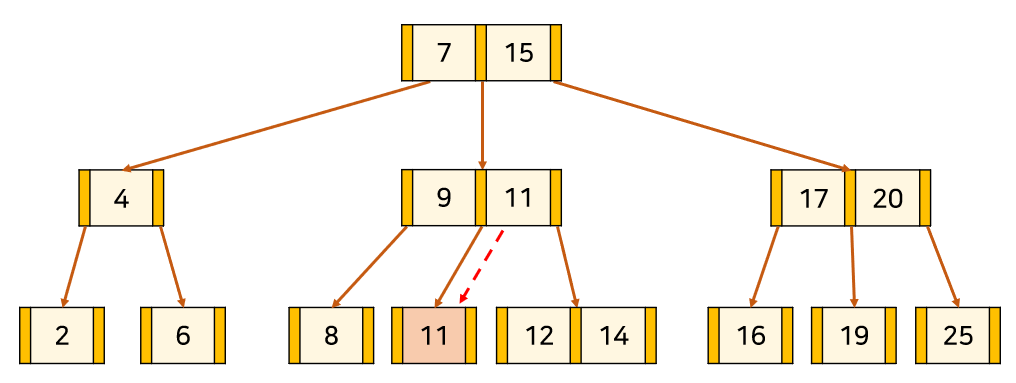
(1-2) 경우
1. 삭제 대상 Key을 Eldest Uncle Key 값으로 덮어쓴다.
2. 삭제 대상의 형제 노드 중 [M/2 <] 인 노드가
오른쪽이라면 Min Key in Right를 Eldest Uncle Key로 위치시키고
왼쪽이라면 Max Key in Left를 Eldest Uncle Key로 위치시킨다.


(1-3) 경우
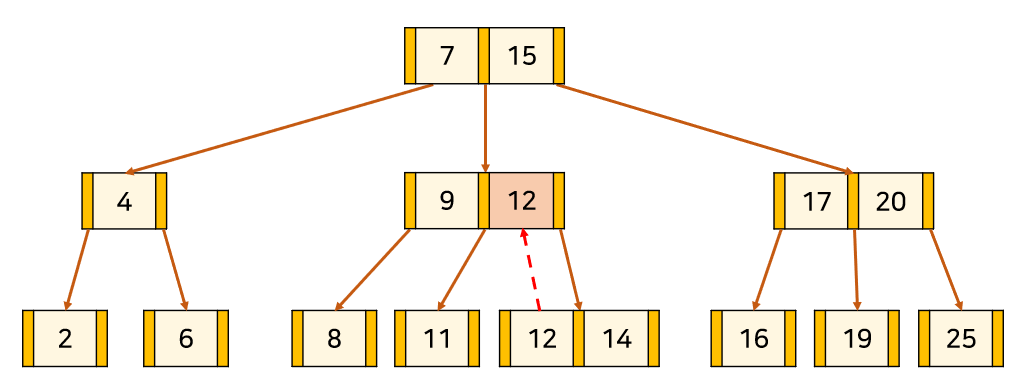
1. 삭제 대상을 제거한다.
2. Eldest Uncle Node를 Eldest Uncle Node의 Min Key in Right보다 작은 쪽에 위치시킨다.

(1-4) 경우
이 경우는 (2-2) 경우와 동일하므로 뒤에서 함께 설명할 계획이다.
(2-1) 경우
1. 삭제 대상과 Max Key in Left 혹은 Min Key in Right 중에 하나와 Swap한다.
2. Leaf Node 제거와 같은 상황이 되었으므로 (1-?)의 방법을 이용해 제거한다.


(2-2) 경우
1. 삭제 대상을 삭제하고 삭제 대상의 양쪽 자식을 하나로 합친다. 합쳐진 node를 n1이라고 명명한다.
2. 삭제 대상의 Eldest Uncle Key를 삭제 대상의 형제 node에 합쳐준다. 합쳐진 node를 n2라고 명명한다.
3. n1을 n2의 자식이 되도록 연결한다.
4-1. 만약 n2의 key 수가 최대보다 크다면 key 삽입 과정과 동일하게 분할을 한다.
4-2. 만약 n2의 key 수가 최소보다 작다면 2번 과정으로 돌아가서 동일한 과정을 반복한다.

'자료구조 및 알고리즘' 카테고리의 다른 글
| 배열 회전 스니펫 (0) | 2023.09.21 |
|---|---|
| Hash Table (0) | 2023.07.24 |
| Heap (0) | 2023.07.24 |
| 레드 블랙 트리 (0) | 2023.07.24 |
| AVL 트리 (0) | 2023.07.24 |