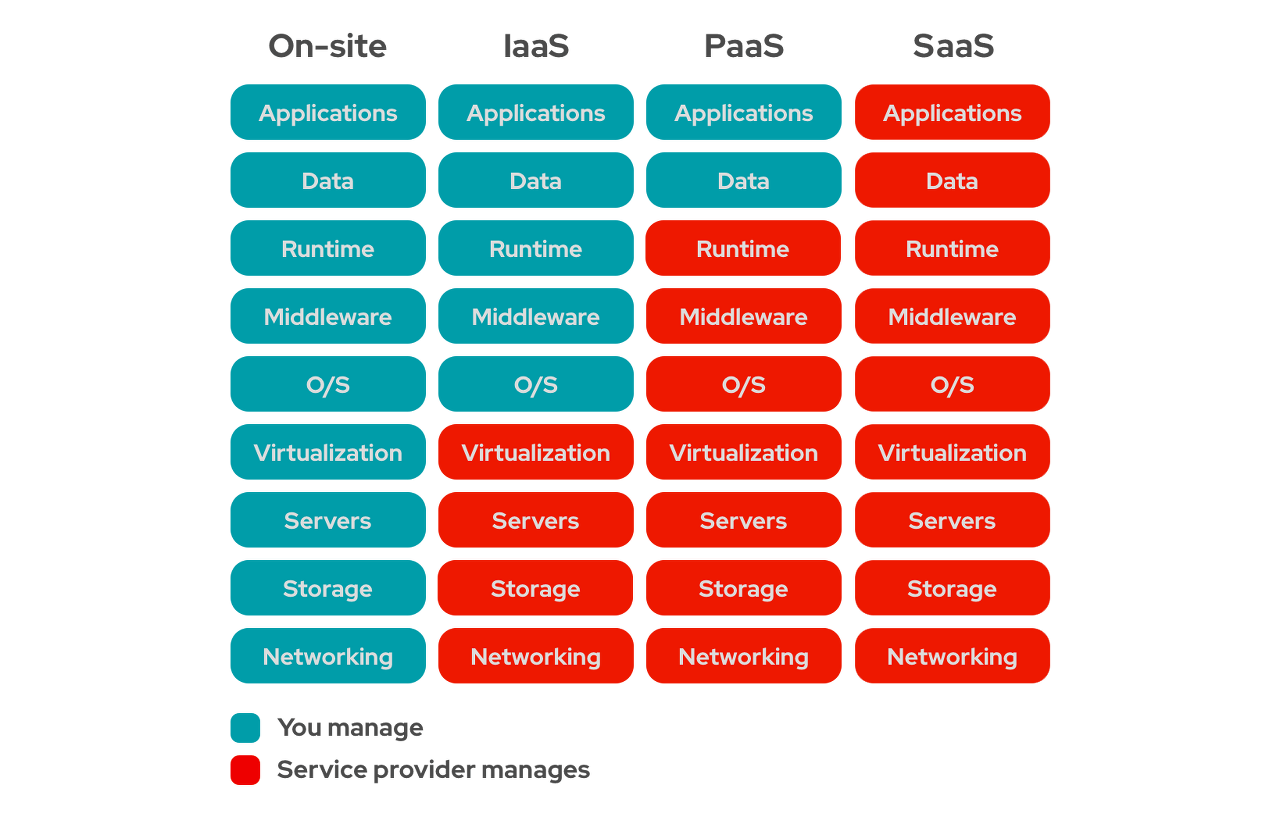
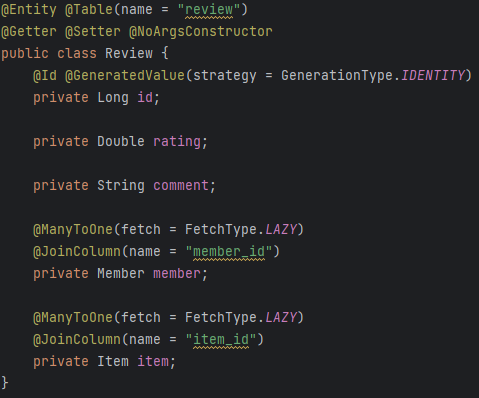
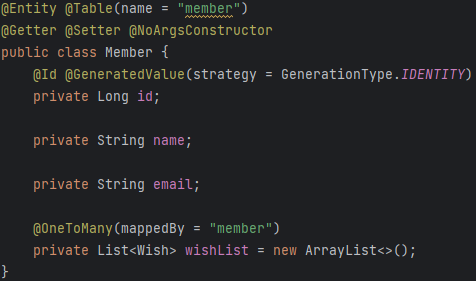
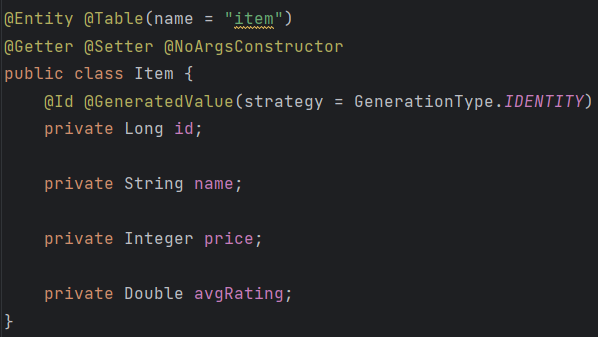
👣 Public Cloud Vs Private Cloud 퍼블릭 프라이빗 컴퓨팅 리소스 소유 여부 X O 제공 방법 Internet 사설 네트워크 비고 가상화 기술로 만든 서비스 그대로 사용 가상 컴퓨팅 기술 직접 구축 👣CSP, Cloud Service Provider - 클라우드 서비스 제공 업체 1. 해외 AWS, GCP, Azure, IBM Cloud, Oracle, Alibaba Cloud, Tencent Cloud 2. 국내 Naver Cloud Platform, NHN Cloud, Gabia.Cloud, Kakao i Cloud, Kt Cloud 👣 Cloud Service 특징 1. 탄력성 및 민첩성: 단 한번의 클릭으로 생성/삭제 및 확장 가능 2. 확장성: 급증하는 서비스, 트래픽에 대..